

Das Document Object Model ist ein grundlegender Bestandteil des World Wide Web. DOM, kurz DOM, ist eine Reihe von API-Standards, die definieren, wie ein Browser ein Webdokument erstellen soll und wie Entwickler Objekte bearbeiten können.
Wir werden ein wenig genauer untersuchen, wie das DOM wirklich funktioniert. Das Modell gibt es schon seit Jahren und befindet sich derzeit auf DOM Level 3 (DOM3-Dokumentation hier). Ein DOM4 befindet sich derzeit im Redaktionsentwurf, und in Kürze werden einige brandneue Daten bereitgestellt. Wir können uns zunächst auf ein kurzes Verständnis der Entstehung des Objektmodells konzentrieren.
Eine Geschichtsstunde
In den frühen Tagen des Webskripts gab es keine Standardmethode, um auf Seitenobjekte zuzugreifen. Dies ermöglichte großen Browsern, eigene Standards und Regeln für die Manipulation von Dokumenten zu erstellen. Software-Unternehmen haben sogar eigene Skriptsprachen wie VBScript von Microsoft und Applescript von Apple geschrieben.
Die frühen Modelle waren sehr begrenzt. Sie können nur auf bestimmte Elemente wie Bilder oder Formulareingaben zugreifen. Im Laufe der Zeit entwickelte das World Wide Web Consortium ein Standardmodell, dem die meisten Mainstream-Softwarehersteller folgten. Insbesondere der Internet Explorer, Netscape, Safari und Opera von Microsoft.
Gegenwärtig hat das DOM viele Überarbeitungen durchlaufen und erlaubt eine sehr genaue Manipulation von Seitenelementen. Mit Skriptbibliotheken wie jQuery und MooTools Entwickler sind in der Lage, viel weniger Zeit mit Fehlern zu verbringen.
Modernes DOM-Scripting heute
JavaScript ist bei Entwicklern mit Abstand die beliebteste Sprache. Ursprünglich als Open-Source-Projekt von Netscape im Jahr 1995 gestartet. Es basiert auf der beliebten Programmiersprache Java und wurde von unzähligen Communities von Webentwicklern modifiziert.
Das DOM selbst ist nur in Situationen nützlich, in denen auf Objekte zugegriffen werden kann. Die meisten standardkonformen Browser unterstützen heute alle Elemente und Methoden für die DOM-Manipulation vollständig. Mit dieser Standardisierung des Objektmodells haben wir eine Zunahme der einfachen Skript- und Seitenfunktionalität erlebt.
Der Dokumentenbaum
Wenn Sie sich das DOM vorstellen, kann es im Vergleich zu einem Baum leicht verstanden werden. Wenn ein Dokument geladen wird, wird jedes Seitenelement als neues Objekt gespeichert. Diese werden manchmal als bezeichnet Knoten des Baumes
Als Beispiel sollte jede richtige HTML - Seite mit einem HTML - Element beginnen, und der gesamte Seiteninhalt sollte in einem geladen werden Karosserie Element. Dies bedeutet, dass Ihre Baumhierarchie bei einem Stamm-HTML-Element beginnt und in den ersten Knoten übergeht Karosserie.
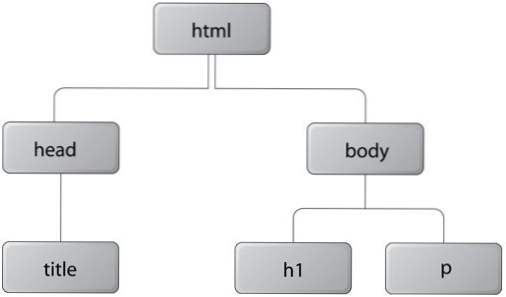
Dies ist eine einfache Idee, aber sie bietet Entwicklern immense Möglichkeiten. Von hier aus können wir viele Arten von Elementen von der Seite ziehen, indem wir einfach auf ihren spezifischen Knoten oder Ort im Dokument zugreifen. Ein kleines Skript könnte geschrieben werden, um alle Bilder von einer Seite zu ziehen und sie zur Speicherung in ein Array zu verschieben.
Von hier aus kann auf jedes Bildelement über JavaScript zugegriffen werden. Im Folgenden habe ich etwas Code hinzugefügt, der 2 Variablen setzt. Das erste hält das dritte Bildobjekt im Speicher, während das zweite das Bild zieht src Zeichenfolge aus dem Element.
Knotenmethoden
Sobald Sie die Möglichkeit haben, Knoten zu manipulieren und darauf zuzugreifen, können Sie Funktionen auf sie schieben. Das Objektmodell dient nicht nur zum Durchsuchen der Seite, sondern auch zum Anwenden neuer Effekte.
Diese nennt man Methoden und sie werden in die DOM-Spezifikation geschrieben. Wenn Sie sich ein knotenbasiertes Baumsystem vorstellen, werden diese Methoden die meisten Verwirrungen beseitigen. Nachfolgend finden Sie eine kleine Beispielliste einiger gängiger Methoden, die Sie für Knoten verwenden können:
nodeA.firstChildnodeA.lastChildnodeA.parentNodenodeA.nextSiblingnodeA.prevSibling
Die meisten dieser Methoden können innerhalb einer Variablendeklaration oder einer Funktionsrückgabeanweisung verwendet werden. Sie senden ein Objekt aus dem DOM in Bezug auf Ihre aktuelle Platzierung zurück.
Die ersten beiden werden den ersten inneren Knoten bzw. den letzten inneren Knoten ergreifen. Das ist das Stichwort Kind soll darstellen, mit nodeA Eltern beider Kinder sein. Dies sollte auch erklären, wie Elternknoten funktioniert, da Sie das Knotenobjekt ziehen können, das sich direkt über Ihrem aktuellen Selektor befindet.

Beide Geschwisterfunktionen kennen die meisten und Zielelemente auf derselben hierarchischen Ebene nicht. Als Beispiel, wenn Sie eine ungeordnete Liste mit 3 durchlaufen haben li Tags, die Sie nur anrufen könnten nextSibling 2 mal vor der Rückkehr Null. Viele dieser Funktionen wurden seitdem von Bibliotheken von Drittanbietern in schnellere und genauere Methoden heruntergefahren.
Elementklassen und IDs
Eine der beliebtesten Methoden zum Abrufen von Objektinformationen ist das direkte Targeting. Wenn Sie HTML-Code geschrieben haben, sollten Sie über Klassen- und ID-Attribute Bescheid wissen. Diese können für jedes Seitenelement festgelegt werden und sind notorisch nützlich, um CSS-Stile anzuwenden.

Wenn Sie diese Attribute erstellen, erkennt das DOM sie als separate Umgebungen vom Gesamtdokument. IDs müssen auf Ihrer Seite eindeutig sein und führen zu Fehlern bei der Skripterstellung, wenn Sie denselben Namen duplizieren. Klassen können unzählige Elemente enthalten, die sich jedoch schnell verklemmen können.
Die beliebte Methode getElementById () wird von den Entwicklern seit einem Jahrzehnt verwendet, um den Prozess der Objektmanipulation zu vereinfachen. Diese Methode verwendet ein einzelnes Zeichenfolgenargument, das den ID-Wert jedes Elements enthält, auf das Sie abzielen möchten. Als solches können Sie ein Bild ändern src Attribut schnell mit ähnlichem Code:
Fortschritte im Modell
Mit der Veröffentlichung der beliebten jQuery-Bibliothek ist es einfacher als je zuvor, leistungsfähige Skripts zu entwickeln. Ältere Funktionen wie getElementById () und getElementsByTagName () sind immer noch zugänglich, jedoch nach den meisten Standards veraltet.
Der schnellste Weg, um mit der Bearbeitung des DOM zu beginnen, ist der Zugriff auf Objekte über jQuery. Ein einfacher Methodenaufruf $ (Dokument) .ready ({}) Alles was Sie brauchen, um eine neue Veranstaltung durchzuführen. Das $() Syntax wird verwendet, um das Ziehen eines beliebigen Objekttyps von der Seite darzustellen.

Dies kann unisono verwendet werden, um IDs und Tags von einer Seite abzurufen. Jeder benötigt einfach die gleichen Symbole, die in CSS-Deklarationen verwendet werden, wie z $ ('# myid') und $ ('. myclass'). Sobald Sie sich in der Ready-Funktion befinden, können Sie mit jQuery beliebig viele Ereignisse und Funktionen abrufen.
Die Bibliothek ist auf Geschwindigkeit optimiert, und da das DOM derzeit schnell voranschreitet, sehen wir große Fortschritte in der Skriptunterstützung. Jeder Knoten wird in einen Objektspeicherplatz geladen, in den sowohl der Webbrowser und Entwickler kann darauf zugreifen.
Fazit
Die Open-Source-Bewegung hat auch wesentlich zur Weiterentwicklung der DOM-Spezifikationen beigetragen. In den letzten 10 Jahren haben wir XML in die Dokumentation aufgenommen und Möglichkeiten zur Definition von Inhaltsfeeds (RSS, Atom usw.) gefunden.
Es ist wichtig, als Webentwickler immer auf dem neuesten Stand zu sein. Das Web schreitet rasch voran, und die neuesten Versionen des Document Object Model zeigen an, wie viel Kontrolle heute verfügbar ist. Wenn Sie sich näher mit DOM-Skripten beschäftigen möchten, bieten wir Sammlungen von jQuery-Tricks und viele Video-Tutorials zum Thema Webdesign völlig kostenlos an!